Observabilidad de API cuando los agentes de IA son quienes más llaman
Gartner dice que el 30% del nuevo tráfico de API proviene de LLM. Cinco patrones de observabilidad para detectar llamadas de agentes, rastrear cadenas de uso de herramientas y establecer límites de velocidad que se ajusten a cargas de trabajo en ráfagas.
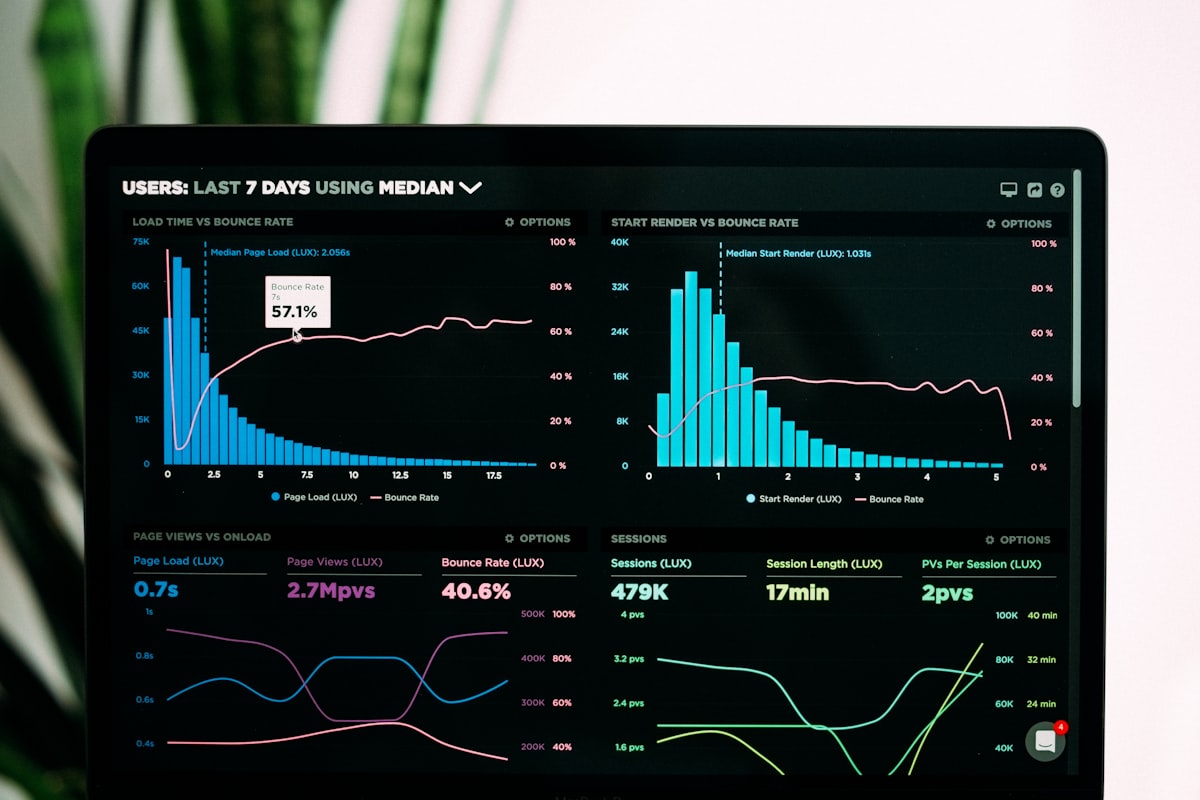
Su panel de API muestra un aumento de tráfico 4 veces mayor a las 3 a. m. Sin campaña de marketing. Sin lanzamiento de producto. No hay noticias sobre piratas informáticos publicar. Un agente de IA descubrió sus puntos finales a través de su servidor MCP y comenzó a ejecutar seguridad de varios pasos auditorías; Búsquedas de DNS, comprobaciones de SSL, análisis de encabezados, 15 puntos finales en ráfagas de 2 segundos, cada 10 minutos.
Esto es normal ahora. Gartner proyecta que el 30% o más del crecimiento de la demanda de API provendrá de agentes impulsados por LLM por 2026. Una encuesta de Cisco encontró que el 89% de las organizaciones ya monitorean el comportamiento de los agentes en producción. el El tráfico está aquí. La pregunta es si su pila de observabilidad puede distinguir entre un ser humano un desarrollador prueba un punto final y un agente ejecuta un flujo de trabajo de 12 pasos a las 3 a.m.
Las herramientas APM tradicionales agregan métricas por punto final. Ellos te muestran que /v1/dns/lookup tengo 500
solicitudes en la última hora, pero no le dirán que 480 de ellas provinieron de 40 ejecuciones de agentes, cada una de las cuales llamó
Búsqueda de DNS, verificación de SSL y análisis de encabezados en una secuencia predecible. Ese punto ciego te cuesta; no puedes
establezca límites de velocidad adecuados, no puede depurar fallas del agente y no puede pronosticar los costos de infraestructura.
Cinco patrones solucionan este problema. Cada uno aborda una brecha específica entre lo que proporciona el APM estándar y lo que usted necesita cuando los agentes son quienes más llaman.
Por qué el APM tradicional pierde el tráfico de agentes
Un desarrollador humano llama a un punto final, lee la respuesta y tal vez llama a otro unos minutos más tarde. Un agente de IA llama de 5 a 15 puntos finales en rápida sucesión, analiza cada respuesta mediante programación y vuelve a intentarlo en caso de error y pasa al siguiente flujo de trabajo. Estas dos formas de tráfico parecen idénticas en cada punto final nivel, pero se comportan de manera diferente en todos los aspectos importantes para las operaciones.
| Dimensión | Tráfico humano | Tráfico de agentes |
|---|---|---|
| Solicitar cadencia | 1-3 solicitudes por minuto, pausas largas | 5-15 solicitudes en 2 segundos, luego inactiva |
| Diversidad de terminales | 1-2 puntos finales por sesión | 5-12 puntos finales por flujo de trabajo |
| Comportamiento de reintento | Reintento manual después de leer el error | Reintento inmediato, retroceso exponencial si está codificada |
| Hora del día | Horario comercial, alineado con la zona horaria | 24/7, a menudo activada por cron en horas impares |
| Manejo de errores | Lee el mensaje de error, ajusta la solicitud | Vuelve a intentar la misma solicitud o salta a la siguiente herramienta |
| Duración de la sesión | Minutos a horas | 2-30 segundos por flujo de trabajo |
Datadog, New Relic y Grafana le muestran percentiles de latencia y tasas de error por punto final. ellos no le muestra "la ejecución del agente #a3f7 llamó a 8 herramientas en secuencia, falló en la herramienta 6, se volvió a intentar 4 veces y se quemó a través de 35 llamadas API para completar una tarea que debería tomar 8." Necesita un rastreo diseñado específicamente para eso.
Plataformas como Langfus, Arize Fénix, Confianza cerebral, y helicón especializarse en la observabilidad de agentes. Rastrean cadenas de uso de herramientas, token consumo y rutas de decisión de los agentes. OpenTelemetry (OTEL) está convergiendo como telemetría estándar formato que conecta estas plataformas a su infraestructura existente.
Patrón 1: detectar llamadas de agentes
Antes de poder observar el tráfico de agentes, debe identificarlo. Tres señales funcionan juntas: Cadenas de agente de usuario, cadencia de solicitud y encabezados explícitos.
Coincidencia usuario-agente
Los marcos de agentes establecen cadenas de usuario-agente identificables. LangChain, CrewAI, AutoGen y Anthropic SDK
todos incluyen nombres de marcos en sus encabezados predeterminados. Solicitudes generadas por SDK de bibliotecas como
axios, node-fetch, y python-requests también señal sin navegador
tráfico.
Solicitar detección de cadencia
Los humanos no llaman a 4 puntos finales diferentes en 5 segundos. Un detector de cadencia del lado del servidor señala a los clientes que llegan a múltiples puntos finales únicos en una ventana corta:
Middleware de detección completa
Combine ambas señales en un middleware que etiquete cada solicitud como agente o humano. Esta etiqueta fluye hacia sus capas de registro, métricas y limitación de velocidad:
La X-Agent-Detected El encabezado de respuesta permite a los desarrolladores de agentes confirmar que sus solicitudes son
siendo clasificado correctamente. Los niveles de confianza influyen en sus reglas de alerta; una confianza "alta"
la detección (encabezado explícito) es definitiva, mientras que "media" (coincidencia UA) puede necesitar confirmación de cadencia.
Patrón 2: rastrear cadenas de herramientas múltiples con OpenTelemetry
Un agente que llame al servidor MCP de botoi para auditar un dominio llegará /v1/dns/lookup, entonces
/v1/ssl-cert/certificate, entonces /v1/headers en cuestión de segundos. En estándar
APM, estas son tres solicitudes separadas y no relacionadas. con un compartido X-Agent-Run-ID encabezado
y OpenTelemetry, se convierten en un flujo de trabajo rastreable.
Cada flujo de trabajo de agente obtiene un intervalo principal. Cada llamada a una herramienta se convierte en un intervalo secundario anidado debajo de ella. en Jaeger, Grafana Tempo o cualquier backend compatible con OTEL, verá la cadena completa: la búsqueda de DNS tomó 45 ms, La verificación de SSL tardó 120 ms, los encabezados tardaron 30 ms y el tiempo total de flujo de trabajo fue de 210 ms. Cuando la herramienta 6 de 8 falla y el El agente lo vuelve a intentar 4 veces, lo ve en el seguimiento en lugar de buscar en registros de puntos finales separados.
La agent.tool_index El atributo en cada tramo le permite reconstruir el orden exacto de
operaciones. Esto es importante al depurar: "¿por qué el agente llamó a la verificación SSL antes de la búsqueda de DNS?"
se convierte en un rastro visible en lugar de un ejercicio de correlación logarítmica.
Patrón 3: límite de velocidad para cargas de trabajo en ráfagas
La limitación de tasas de ventana fija castiga a los agentes. Un agente envía 15 solicitudes en 2 segundos para completar un flujo de trabajo y luego se queda en silencio durante 58 segundos. Una ventana fija de "60 solicitudes por minuto" tiene mucho de espacio, pero una ventana fija de "5 solicitudes cada 5 segundos" bloquea al agente en la solicitud 6, incluso aunque la tasa sostenida está muy por debajo del límite.
El depósito de tokens resuelve esto. La capacidad del depósito controla el tamaño de la ráfaga (cuántas solicitudes puede realizar un agente). dispara en una ráfaga), y la tasa de recarga controla el rendimiento sostenido (qué tan rápido se recupera el cubo). Dos parámetros que se relacionan con el funcionamiento de los agentes.
La idea clave: los agentes necesitan una mayor capacidad de ráfaga y una tasa sostenida comparable. Un usuario humano con un depósito de 5 tokens y una tasa de recarga de 0,5 tokens/segundo, puede realizar 5 solicitudes rápidas y luego una cada 2 segundos. Un agente con un depósito de 20 tokens y una recarga de 2 tokens por segundo puede iniciar un flujo de trabajo de 15 puntos finales en una ráfaga y rellene el cubo para la siguiente ejecución 10 segundos después.
Así es como la API de botoi maneja el tráfico mixto. Las solicitudes anónimas (sin clave API) obtienen una ráfaga de 5 solicitudes/min. con un límite de 100 solicitudes/día, rastreado por IP. Las solicitudes autenticadas en planes pagos utilizan el depósito de tokens de Unkey en el borde con ráfagas más altas y límites sostenidos por nivel.
Patrón 4: contexto de uso de herramientas de registro con encabezados de correlación
una solicitud para /v1/dns/lookup de forma aislada no dice nada sobre la intención. La misma petición que
El paso 1 de una auditoría de seguridad de 8 pasos le dice todo. Los encabezados de correlación cierran esta brecha.
Dos encabezados contienen todo el contexto que necesitas:
X-Agent-Run-ID: un UUID que agrupa todas las solicitudes en un único flujo de trabajoX-Agent-Tool-Index: la posición de esta llamada en la cadena de herramientas (1, 2, 3...)
Del lado del cliente, el agente adjunta ambos encabezados a cada solicitud en un flujo de trabajo:
En el lado del servidor, registra ambos encabezados con cada solicitud. Reconstruir lo que hizo un agente se convierte en
una sola consulta: "muéstrame todas las solicitudes con X-Agent-Run-ID = abc-123 ordenado por
X-Agent-Tool-Index." Sin correlación de marcas de tiempo, sin coincidencias de IP, sin conjeturas.
Si sus agentes usan el servidor MCP de botoi, el protocolo MCP ya agrupa las llamadas a herramientas en sesiones. el
servidor MCP en api.botoi.com/mcp reenvía la clave API a través de encabezados, y puede extender
para pasar un ID de ejecución que persiste en las 49 herramientas disponibles.
Patrón 5: alerta sobre anomalías específicas del agente
Las alertas estándar se activan sobre tasas de error HTTP y percentiles de latencia. Se activan alertas específicas del agente patrones de comportamiento que indican que algo anda mal con el agente en sí, no con su API.
Tres tipos de alerta detectan las fallas más comunes de los agentes:
- Orden de herramientas inesperado: un agente llamado verificación SSL antes de la búsqueda DNS, lo que sugiere un error lógico en el paso de planificación del agente
- Se detectó un bucle de reintento: el mismo punto final fue atacado 5 o más veces en 10 segundos desde la ejecución de un agente, lo que indica que el agente no está leyendo respuestas de error
- Aumento de costos: la ejecución de un agente superó las 50 llamadas API, lo que significa que un bucle o una alucinación está impulsando el consumo desbocado
La alerta de bucle de reintento es la señal de mayor valor. Un agente que recibe un error 400 (entrada incorrecta) y Vuelve a intentar la misma solicitud 20 veces, supera los límites de velocidad y no produce ningún resultado útil. atrapando Esto en segundos en lugar de minutos ahorra tanto su presupuesto de infraestructura como el del operador agente. Cuota API.
En conjunto: una pila de observabilidad para tráfico mixto
Aquí está la pila que cubre los cinco patrones:
| Capa | Herramienta | lo que proporciona |
|---|---|---|
| Detección de agentes | Middleware personalizado (Patrón 1) | Etiqueta cada solicitud como agente o humano |
| Seguimiento distribuido | OpenTelemetry + Jaeger o Grafana Tempo | Une cadenas de múltiples herramientas en trazos únicos |
| Limitación de velocidad | Cubo de fichas (Patrón 3) | Límites amigables para ráfagas por tipo de persona que llama |
| Telemetría del agente | Langfuse, Arize Phoenix o Helicone | Uso de tokens, cadenas de herramientas, rutas de decisión de los agentes |
| alertando | Reglas personalizadas sobre datos de seguimiento (Patrón 5) | Detecta bucles de reintento, secuencias inesperadas y picos de costos. |
Si ya ejecuta Datadog o Grafana para su API, no necesita reemplazarlos. Añade el Capa de instrumentación de OTEL en la parte superior, canaliza los seguimientos etiquetados por el agente a un panel de control dedicado y crear reglas de alerta sobre los atributos específicos del agente. Las métricas existentes por punto final permanecen Útil para el monitoreo de infraestructura. Los nuevos seguimientos con reconocimiento de agente responden a las preguntas que El ingeniero de guardia pregunta a las 3 a.m.: "¿Qué está haciendo este agente? ¿Por qué lo vuelve a intentar? ¿Debo hacerlo?". bloquearlo?"
Conclusiones clave
- Detecta primero, observa segunda. Etiquetar cada solicitud como agente o humano usando Patrones de User-Agent, detección de cadencia y encabezados explícitos. Todo depende sobre esta clasificación.
- Rastree flujos de trabajo, no puntos finales. La unidad de trabajo de un agente es una multiherramienta. cadena, ni una sola llamada API. Los tramos padre/hijo de OpenTelemetry crean flujos de trabajo de agentes objetos de primera clase en su backend de seguimiento.
- Cubo de fichas sobre ventana fija. Los agentes estallan. El depósito de tokens admite ráfagas al mismo tiempo que se imponen límites sostenidos. Haga coincidir la capacidad del cucharón con la cadena de herramientas más larga esperada.
-
Los encabezados de correlación son baratos y potentes.
X-Agent-Run-IDyX-Agent-Tool-Indexconvierta registros de solicitudes opacos en flujos de trabajo de agentes legibles con una única consulta a la base de datos. - Alerta sobre el comportamiento, no sobre el volumen. Bucles de reintento, pedidos inesperados de herramientas y Los recuentos de llamadas descontroladas detectan problemas reales antes de que se conviertan en incidentes.
La API de Botoi maneja el tráfico humano y de agentes en más de 150 puntos finales y un servidor MCP de 49 herramientas.
Cada respuesta incluye X-RateLimit encabezados. Si está creando un agente que llama
API externas, pase una X-Agent-Run-ID encabezado, respetar los encabezados de límite de tarifa, y
brinde a su proveedor de API las señales que necesita para que su agente siga funcionando sin problemas. Prueba el
documentos API interactivos
o conecta tu asistente de IA a través del
servidor MCP ver
estos patrones en la práctica.
FAQ
- ¿Cómo puedo saber si un agente de IA está llamando a mi API?
- Busque tres señales: cadenas de User-Agent que contienen nombres de marcos de agentes (langchain, crewai, autogen), patrones de solicitud en ráfagas donde se llaman de 5 a 15 puntos finales en secuencia rápida con espacios de menos de un segundo y encabezados de correlación como X-Session-ID o X-Agent-Run-ID. También puede comprobar las secuencias de uso de herramientas en las que las búsquedas de DNS, SSL y encabezados se realizan en un orden predecible en cuestión de segundos.
- ¿Por qué el APM tradicional pierde el tráfico de agentes de IA?
- Las herramientas APM tradicionales agregan métricas por punto final. Los patrones de tráfico de agentes abarcan múltiples puntos finales en una única operación lógica. Un agente de auditoría de seguridad que llama a la búsqueda de DNS, luego a la verificación de SSL y luego al análisis de encabezados en 2 segundos parece tres solicitudes no relacionadas en Datadog o New Relic. Necesita un seguimiento distribuido con un ID de correlación compartido para vincular esas llamadas en el flujo de trabajo de un agente.
- ¿Cuál es el mejor algoritmo de limitación de velocidad para el tráfico de agentes de IA?
- El depósito de tokens funciona mejor para cargas de trabajo de agentes. Los agentes envían ráfagas de 5 a 15 solicitudes en segundos y luego quedan inactivos. El depósito de tokens permite ráfagas controladas hasta un límite de capacidad y al mismo tiempo aplica una tasa de recarga sostenida. Se corrigieron las pausas que limitan la velocidad de la ventana porque un agente puede agotar el límite completo de la ventana en 2 segundos y luego permanecer inactivo durante 58 segundos.
- ¿Cómo puedo rastrear un flujo de trabajo de agente de IA de varios pasos a través de llamadas API?
- Haga que el agente envíe un encabezado X-Agent-Run-ID con cada solicitud en un flujo de trabajo. En el lado del servidor, cree un intervalo principal de OpenTelemetry para cada ID de ejecución única y anide intervalos de puntos finales individuales debajo de él. Esto le brinda una vista de seguimiento única que muestra que la búsqueda de DNS tomó 45 ms, la verificación de SSL tomó 120 ms y los encabezados tomaron 30 ms, todo bajo el flujo de trabajo de un solo agente.
- ¿Debería establecer límites de velocidad diferentes para los agentes de IA y para los usuarios humanos?
- Sí. Los usuarios humanos realizan de 1 a 3 solicitudes por minuto con largas pausas entre ellas. Los agentes realizan de 5 a 15 solicitudes en una ráfaga de 2 segundos y luego nada durante minutos. Una ventana fija por minuto castiga injustamente a los agentes. Utilice un depósito de tokens con una mayor capacidad de ráfaga (p. ej., 20 solicitudes) y una tasa sostenida más baja (p. ej., 5 tokens por segundo) para que los agentes puedan completar los flujos de trabajo sin sufrir errores 429.
Empieza a construir con botoi
150+ endpoints de API para consultas, procesamiento de texto, generacion de imagenes y utilidades para desarrolladores. Plan gratuito, sin tarjeta de credito.